MySQL InnoDB引擎存储结构
InnoDB行记录结构
Compact格式

这里的变长头Varible Length部分主要有两部分组成:
- null列表 用来表示null值数据列的比特数组;
- 还有由1Byte或者2Byte(保存在溢出页)组成的列表表示变长字段的长度。
Record Header部分用来保存roll_ptr、trx_id和row_id(如果不存在主键),列的个数n_owned和删除标识delete_flag也保存在此
数据列保存实际的行数据,最大可以保存768B(实际数据数据)+20B(指向溢出页记录的指针),超过长度的数据会被保存到溢出页Overflow Page中。
当一列数据为null是,不会在数据列中保存任何记录,会将varible-length中的null列表对应的索引值置为1。
InnoDB数据页结构
InnoDB中每个页的大小是16K,每一条行记录对应页中一条Record,保存在User Records部分中
InnoDB中数据页格式如下
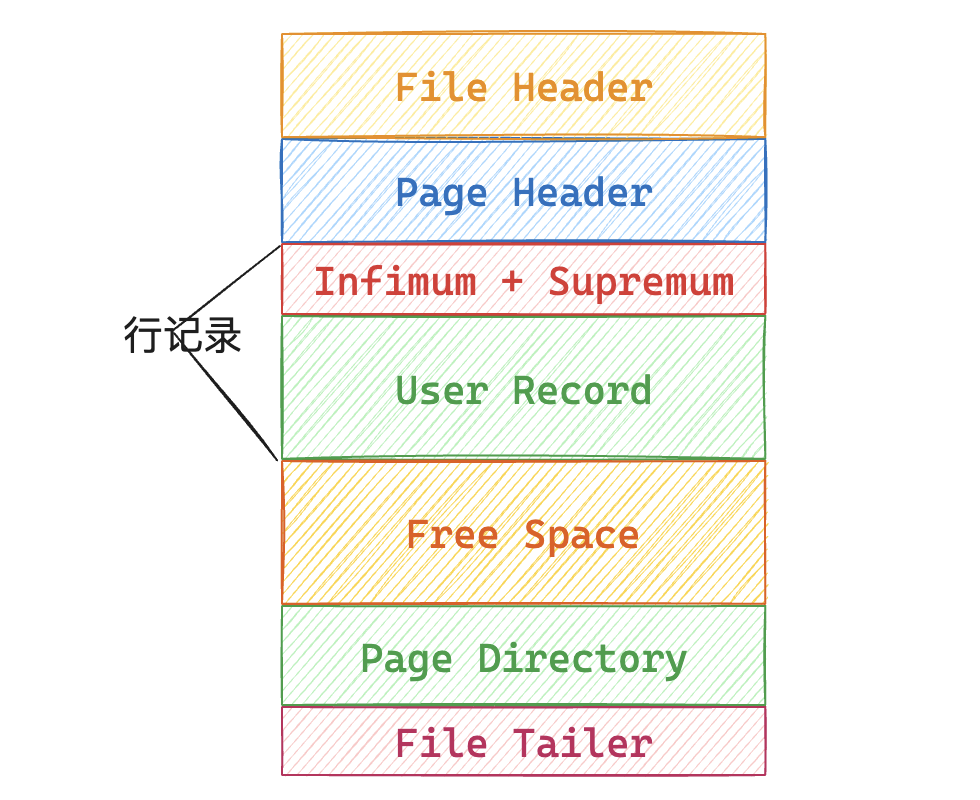
File Header中保存prev和next指针,将逻辑相邻的页组成双向链表Page Header只有数据页才会有,用户记录当前页属于那个索引、页中的记录数等Infumum和Supremum是标兵节点,用于标识页中行记录的头节点和尾节点User Record实际数据保存位置,是一个由infimun开头supremum结尾的单项链表Free Space空闲空间,是一个链表结构,当一条记录被删除是会被添加到空闲空间链表中Page Directory用于查找行记录的索引File Tailer保存校验信息等
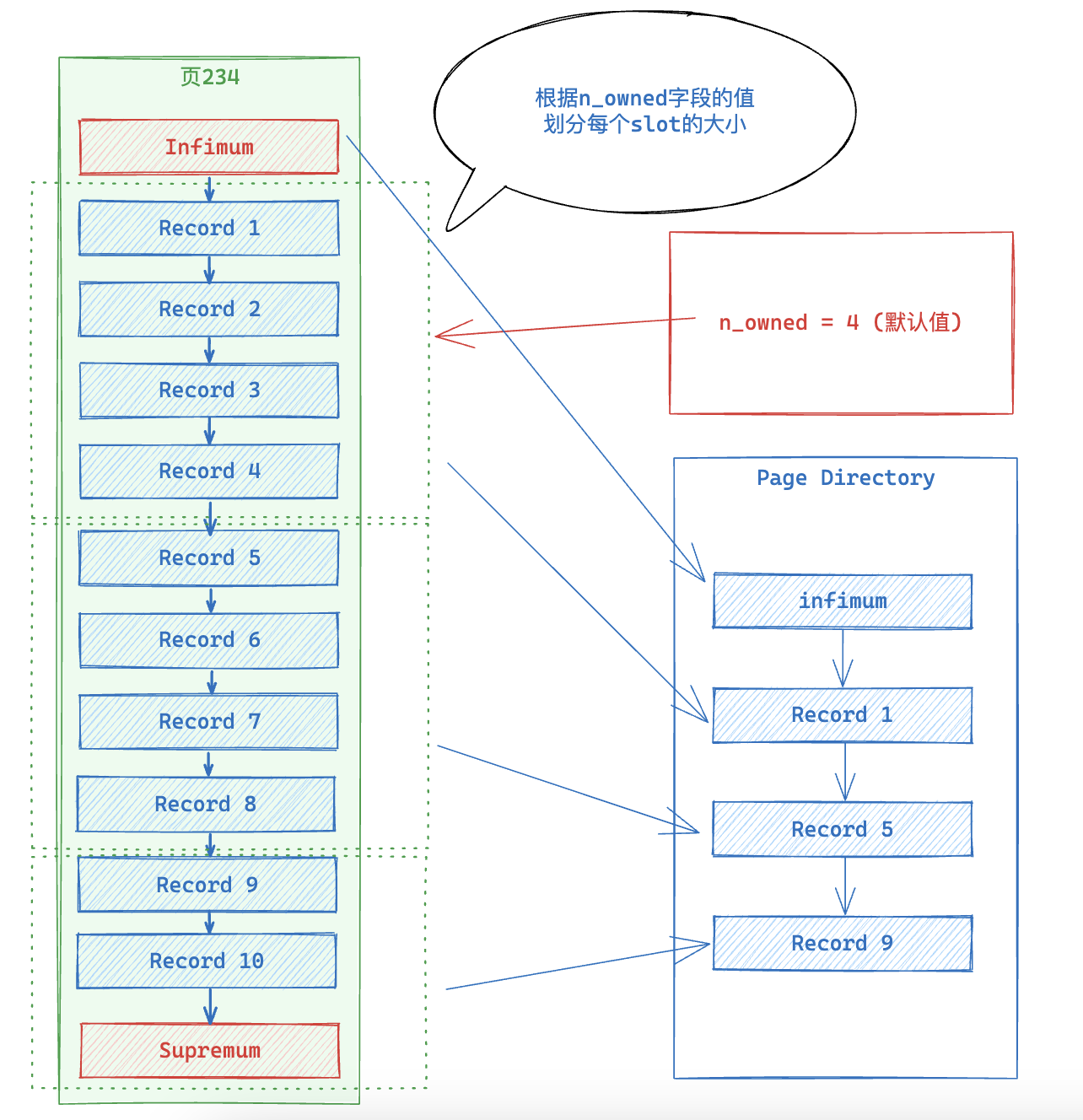
Page Directory存放着page中的记录索引,注意的是这里保存的是行记录的指针(称为目录槽Directory Slots),除了infimum和supremum记录,其他的User Record按照4(由n_owned字段定义,范围[4,8],默认为4)个一组进行分组,每组的第一个记录的指针保存在目录槽中。这样在页中就可以使用二分查找行数据。
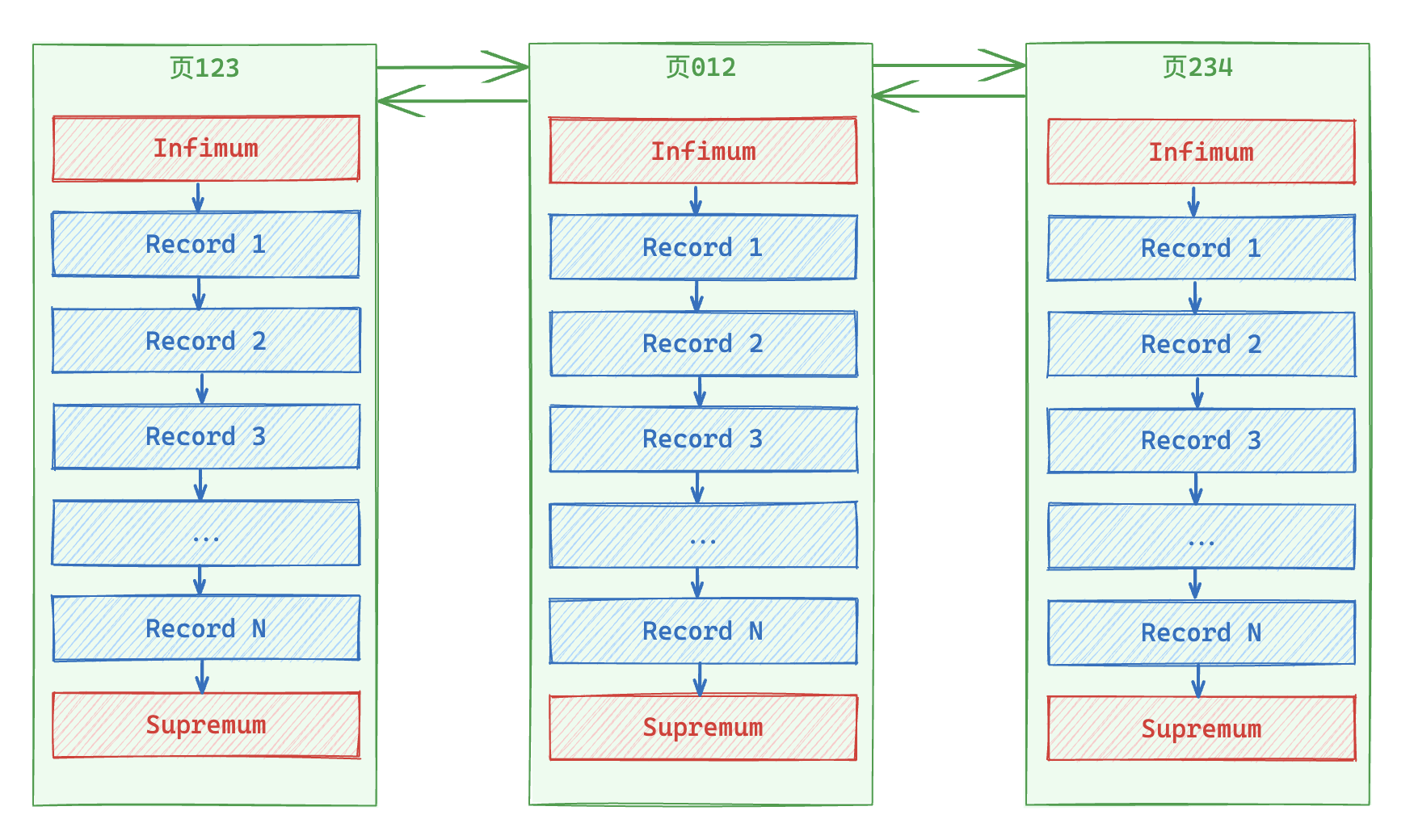
相邻页的组成结构
InnoDB的页通过PageHeader的prev和next指针组成双向链表
MySQL的索引
InnoDB索引使用B+树的结构方式,为聚簇索引。
InnDB主键索引示意图如下:
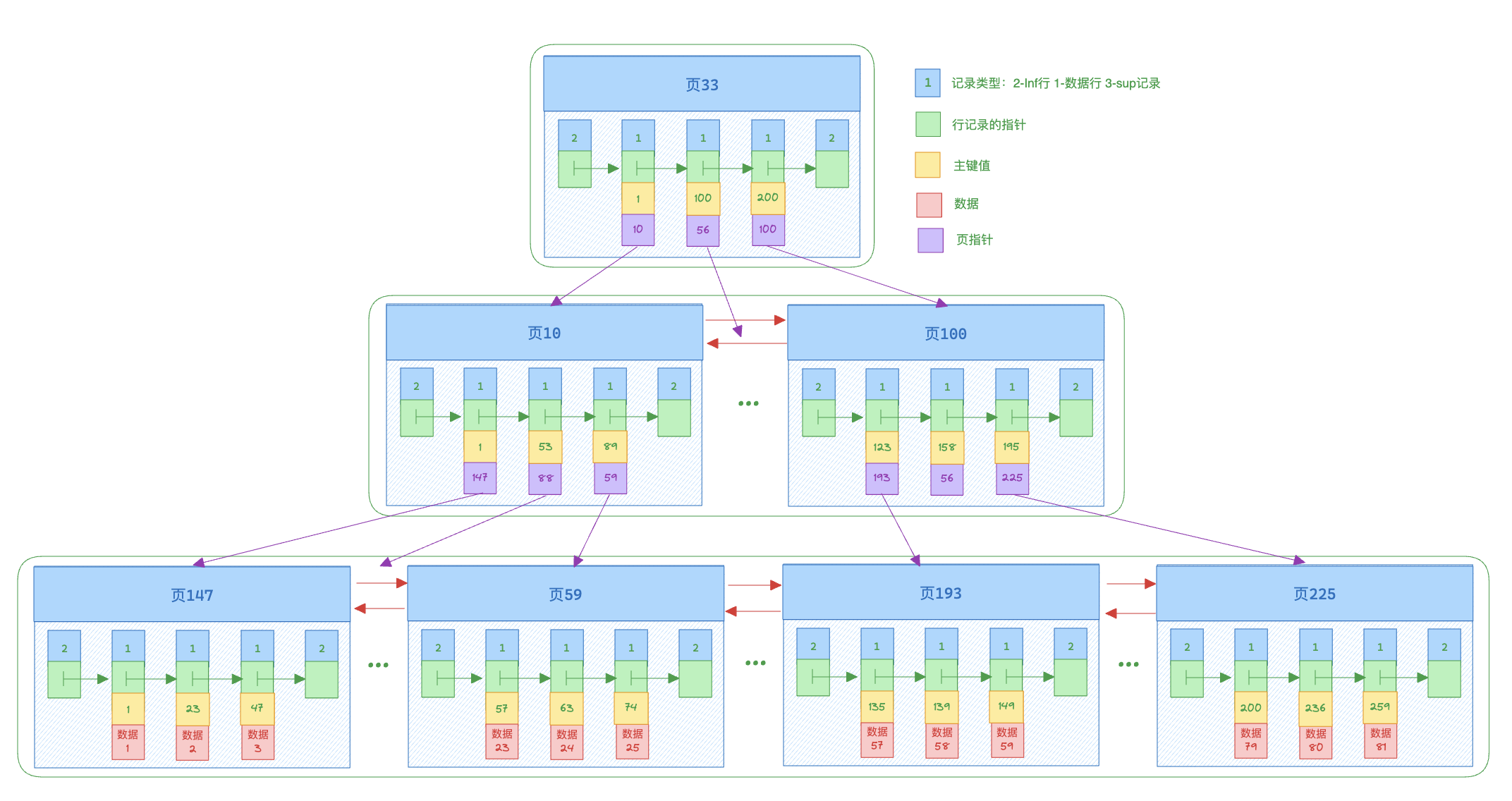
索引中每一页称为节点,分为叶子节点和非叶子节点,非叶子节点保存索引的主键值和下一层页的地址,页子节点保存真实的行数据,同一层相邻节点之间通过双向链表进行连接。
辅助索引/二级索引
聚簇索引又叫主键索引,上面图示的主键索引就是聚簇索引,他的叶子节点记录的数据是完整的数据。但是表中除了主键还可能有他列作为索引,这些就是二级索引,二级索引也会创建B+树,只不过叶子节点不再需要存储所有列的内容,只需要存储主键和索引列的值两项即可
二级索引示意图:
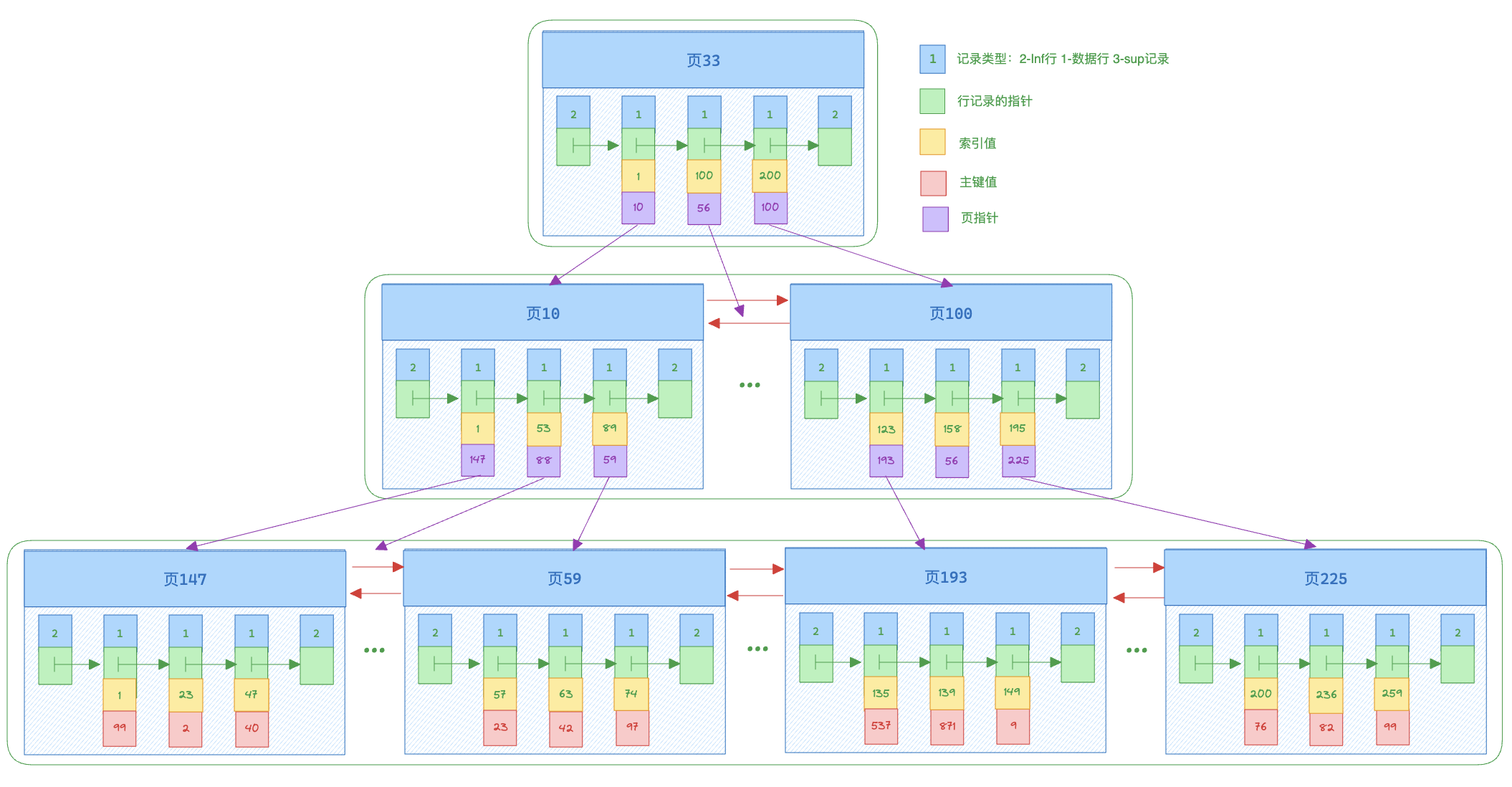
当我们通过索引值进行查找时,找到的是记录对应二级索引和主键索引值,还需要通过一次回表查询主键索引拿到完整的记录值。
当我们一次查询的字段刚好完全在二级索引中时,我们完全就可以直接通过二级索引拿到值,从而减少一次回表查询的消耗,这种操作叫做索引覆盖。
联合索引
联合索引是将多个列同时作为索引,底层也是B+树,和普通二级索引并无太大不同。
联合索引示意图:
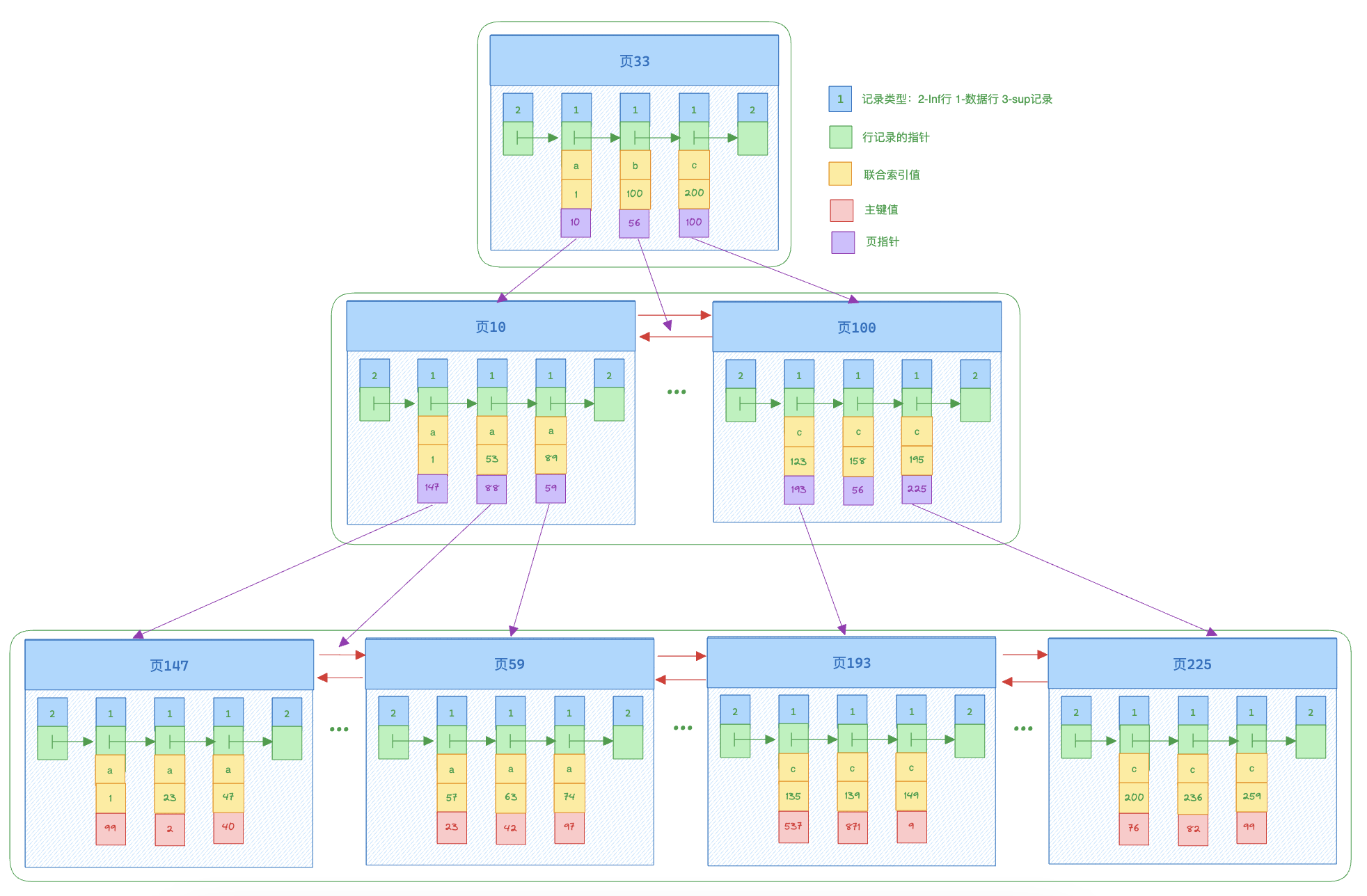
当我们走联合索引(a, b)通过条件查询数据时,如果同时存a,b的条件查询,例如a>1,b<10MySQL会先拿到所有满足a条件的数据,再回表查询到索引的完整记录值,最后过滤满足条件的数据返回。
在MySQL5.6及以后,当我们执行上面操作时,MySQL会直接在联合索引中过滤b<10的数据,这样减少了回表查询的次数,可以大幅度提高查询性能,这中优化方式叫做索引下推。