一个指令在MySQL执行过程
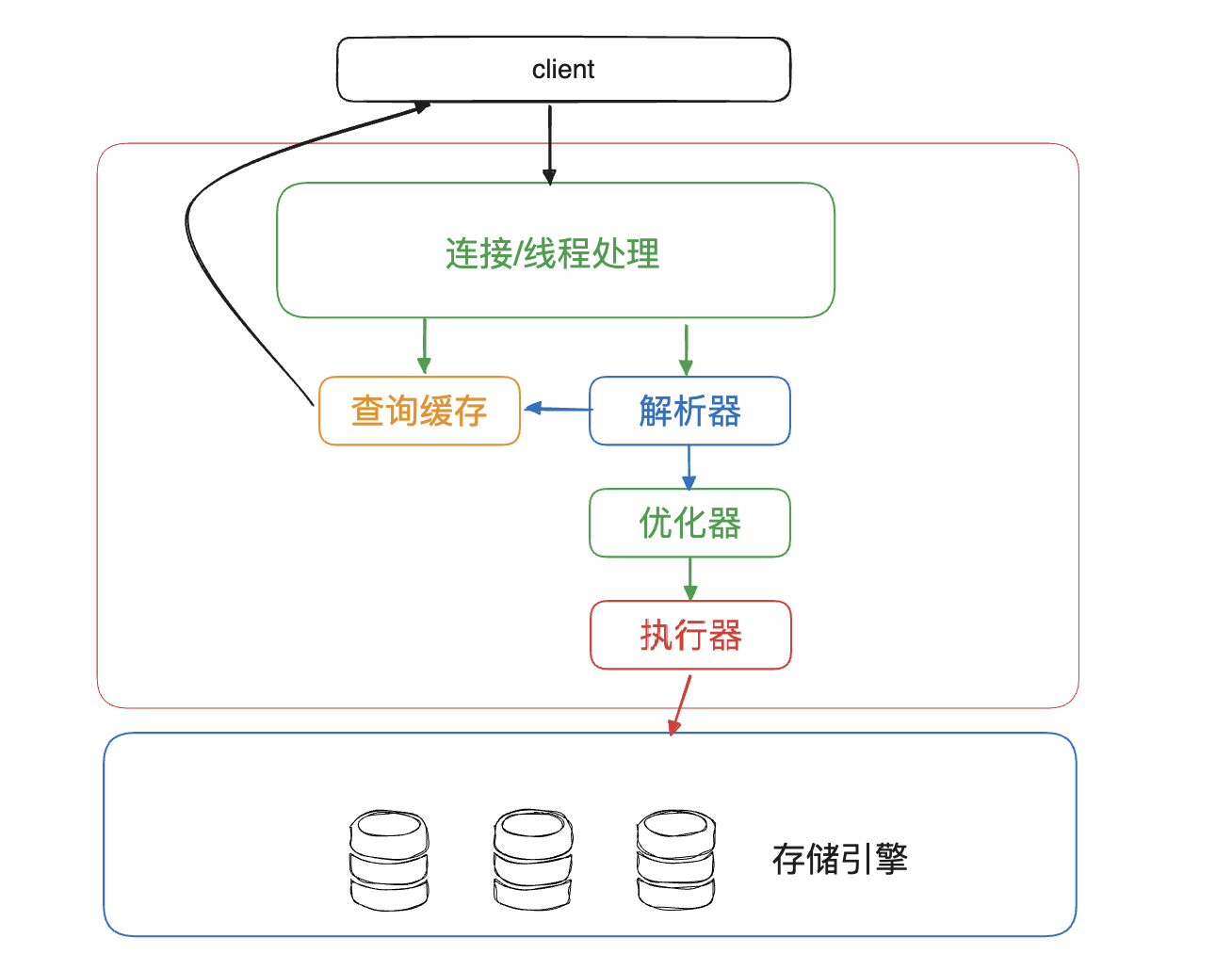
MySQL整体架构
MySQL可以分为两个部分:MySQL Server和存储引擎
其中MySQL Server层包包括连接器、查询缓存、解析器、优化器和执行器等。Server层包含绝大多的核心服务及功能,包括内部函数等。所有独立于存储引擎的功能如视图、触发器等也在这里实现。
存储引擎层负责数据等存储和读取,最常用的是InnoDB引擎。
用户通过MySQL的连接/线程处理器进行连接,然后通过查询缓存、解析器、优化器来生成视图、触发内置函数和进行存储过程等,最后由执行器通过api操作对应的存储引擎完成数据的存储和提取。
连接器
使用MySQL的第一步是建立连接,用户通过TCP Socket经过账户密码等方式完成身份验证建立连接。
一旦连接成功,连接器将查找用户当前的权限并保存在此次连接中,这意味着后续用户权限变更的话当前连接依旧会使用原有权限。
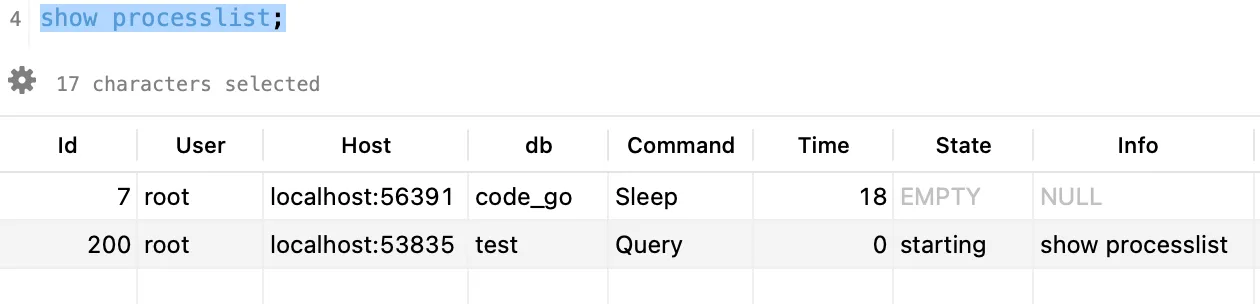
你可以通过show processlist命令查看当前MySQL的连接,其中Sleep的代表该连接处于空闲状态。如果连接空闲时间超过wait_timeout(默认为8小时)的话,该连接将会被关闭。
然而当存在大量长连接的话,可能会导致MySQL内存占用量非常高,甚至是OOM。这时由于在每次执行SQL大使用,都会在连接对象中占用临时内存,而这些临时内存只有在连接终止是才会被回收。
因此,我们可以 1. 周期性的重新连接 2.在MySQL5.7以上版本中使用mysql_reset_connection命令在执行一些SQL后重置连接,这个命令只会将连接重置为刚开始连接的状态,以回收临时内存。
查询缓存
一旦建立好连接,就可以执行SQL了,这时就会首先走到查询缓存。
当接收到查询请求的时候,MySQL会判断这个查询请求先前是否执行过,先前执行过的请求将会被以键值对的方式保存在内存中的查询缓存中,当发现查询缓存中保存有查询语句时候就可以直接返回保存在缓存中的结果。若是缓存中没有找到,就会执行后续步骤并将执行的结果保存到内存中。
然而在大多数情况下,查询缓存并不会提高多少性能甚至会带来反作用,因为缓存失效率非常高--每当更新操作时,所有的查询缓存都会被置为无效并清除。在大量更新操作时,查询缓存的命中率非常低,所以只有当表的值不会频繁变动时才推荐开启查询缓存。
MySQL默认不会开启查询缓存,如果你要将某一查询语句结果添加到查询缓存中,可以使用显式使用SQL_CACHE
select SQL_CACHE * from T where id = 1;
注:在MySQL 8.0版本中,查询缓存已经被完全移除
解析器
如果查询缓存没有命中的话,会执行到解析器。
select id from user where id=123
解析器首先会进行词汇分析,来识别每个词代表什么,例如上面的SQL:
- 首先通过select关键字识别这时一个查询语句
- 然后通过字符串user得到查找的是user表
- 然后解析到查找字段为id
当词汇分析结束后,会进行语法检查,根据词汇分析的结果判断是否满足MySQL的语法规则。
隐式转换
优化器
解析完成后,MySQL已经知道你要干什么了,但在执行器执行前还需要进行优化:要知道该怎么做。
优化器决定着当有多个索引是选择哪一个,当进行join操作时表的连接顺序。
当优化器优化完成后,会决定好一个执行计划,然后使用这个执行计划进行执行器的执行。
执行器
MySQL通过解析器知道你要做什么并且通过优化器知道怎么做后,将会正式进入执行步骤。
首先,MySQL会进行权限校验,判断是否有对应表的查询权限,然后通过存储引擎提供的接口拿取数据。
以上面的查询条件为例,当没有索引的情况下:
- 执行器通过存储引擎捷克拿到第一行数据,判断id是否是123,如果是就将这行数据保存到结果集中,否则就跳过
- 执行器重复上面操作,直到抵达做后一行
- 最后,执行器将结果集返回给客户端
当存在索引的情况下也是类似的:执行器会抓取满足条件的行,然后不断遍历知道所有的行都被查找过,这些接口都是由存储引擎进行实现的。
在数据库的漫查询日志中会有一个名为rows_examined的字段代表着执行语句过程中扫描了多少行,在每次抓去一行时都会累加。有些时候调用存储引擎可能会扫面多行数据,rows_examined大小不一定完全等于时机扫描数。